Multimodal API support, additional architectures, and more!
Published 2025-05-10
That's right: we're finally shipping multimodal image input support for our API! For all models that support multimodal image input, you can now use our OpenAI-compatible API to chat with them about images you input. We've also shipped support for several new LLM architectures, significantly improved our UI, and made large performance and reliability improvements for on-demand models. We're working on multimodal image support in our UI as well, so stay tuned!
- Multimodal API support
- More model architectures
- Improved UI
- Better performance and reliability for on-demand models
- Future plans
Multimodal API support
After much demand, we're finally launching support for multimodal image input in our API! If you use our API, you can now ask LLMs that support multimodal image input (like Llama 4) questions about images. For example, let's ask Llama 4 Scout about this image:

We'll use a curl command in Bash to ask it to describe the image:
curl -X POST "https://api.synthetic.new/v1/chat/completions" \
-H "Content-Type: application/json" -H "Authorization: Bearer ${SYNTHETIC_API_KEY}" \
-d '{
"model": "hf:meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Describe the contents of this image."
},
{
"type": "image_url",
"image_url": {
"url": "https://synthetic.new/images/totoro.jpg"
}
}
]
}
],
"max_tokens": 300
}' 2>/dev/null | jq -r ".choices[0].message.content"
In response, we get:
The image depicts a scene from the animated film "My Neighbor Totoro," featuring a young girl and two fantastical creatures in a forest setting.
- The girl is positioned on the left side of the image, wearing a yellow hat with a red ribbon tied around it, a white shirt, and a pink dress. Her brown hair is styled in pigtails, secured with red ribbons. She is crawling on her hands and knees, gazing at the creatures.
- A small, white creature with a round body and two large eyes is situated in front of the girl, looking up at her.
- On the right side of the image, a larger, blue creature with a round belly and two small ears stands. It has a large acorn on its back and appears to be walking or floating through the forest.
The background of the image features a dense forest with numerous trees and green foliage. The overall atmosphere suggests that the girl has encountered these magical creatures while exploring the woods.
We're launching this to the API first, because it's ready! We expect to launch UI for multimodal image input in the coming weeks.
More model architectures
Since our last newsletter, we've launched support for several new architectures!
- Gemma 3
- Llama 4
- Qwen 3
- Mistral 3
We're keeping Llama 4 Scout and Maverick always-on, as well as Qwen 3's largest model, Qwen/Qwen3-235B-A22B. We've also added deepseek-ai/DeepSeek-V3-0324 to our always-on list: it's really good!
Improved UI
Our UI has changed a lot over the past few weeks, as you may have noticed. Our goal is to make it simpler to quickly start conversations with LLMs: now, when you go to synthetic.new, you'll automatically land on a new chat page for the last model you used in the UI. And hitting the + icon in a thread will automatically create a new thread with the model from your current thread! Here's what our new chat page looks like:
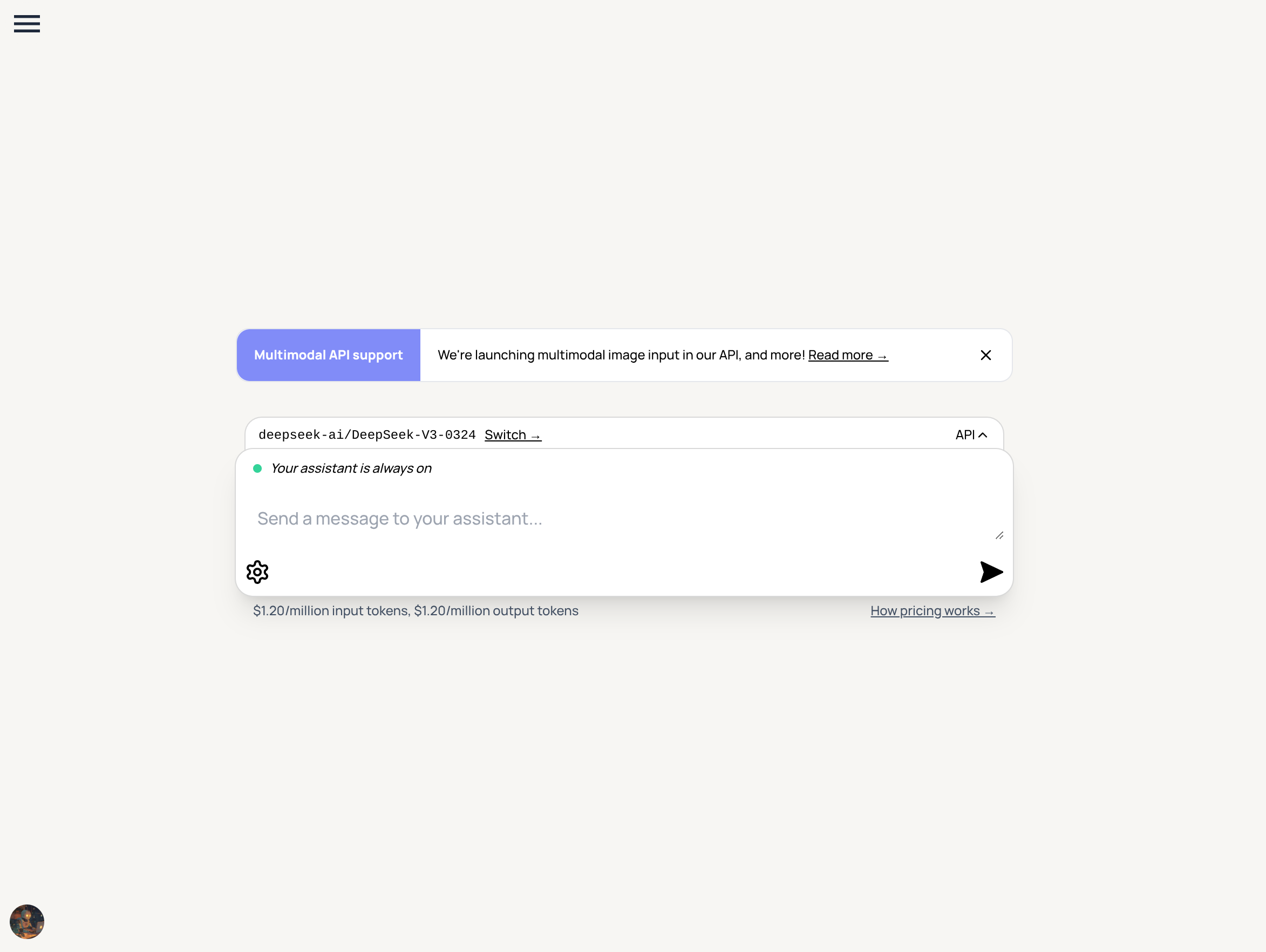
You can also share links directly to models you like! For example, synthetic.new/hf/deepseek-ai/DeepSeek-V3-0324 will take you directly to DeepSeek-V3-0324.
Better performance and reliability for on-demand models
We overhauled how we launch on-demand models, and now use a new GPU provider on our backend and have significantly better caching in place. Launching on-demand models should be much faster now, and work more reliably. It's still not fast to launch a model on-demand — we still need to load potentially hundreds of gigabytes of weights into GPU VRAM, and compile them! — but it should be much better than it used to be.
Future plans
If you made it this far: thanks for reading! We're hard at work on more improvements, including but not limited to:
- Supporting image input for the UI! We launched it to the API first since it was ready there faster, but we're working on UI for supporting image input as well.
- Shareable chat threads! Sometimes you just want to shoot a chat thread you've been having with a model over to a friend or coworker, and we want to support this easily (opt-in of course, for privacy). It's just not the same to copy/paste the entire thread and try to send it to someone: it's much easier to just send them a link.
- Dark mode! We've had a lot of requests for this one and it's on our radar. Our designer is working hard at improving the UI, and one of the items on her agenda is a good set of colors for dark mode.
- Community Discord! This has been a to-do for a bit for us, but we promise it's actually coming.
- More backend and UI improvements. Maybe not the most exciting line item, but we're always bugfixing.
If you have any thoughts or feedback, please continue to reach out at [email protected]. We appreciate all the emails we've gotten so far!
— Matt & Billy